Dokumentasjon av NIB
Dokumentasjonen er delt inn i følgende sider:
- Overordnet oversikt over hele systemet (denne siden)
- Datamodell-oversikt for OpenAlex
- Datamodell-oversikt for WoS
- Endringslogg for oppdatering av WoS/OpenAlex
- Pilot-script i R
Generelt om basene
NIB inneholder to hovedkilder: WoS og OpenAlex, som begge ligger i en postgresql-database på en egen server. (Se base-oversikt fra pgadmin under).
Hver kilde-base kan forekomme i tre hoved versjoner:
- Produksjon, stabil versjon hvor evt endringer i datamodell o.l. meldes i god tid. Disse navngis med _prod.
- Test – Dette er versjoner som i utgangspunktet er relativt stabile, men hvor det kan forekomme små og store endringer på kort varsel. Navngis med _testNN (feks wos_test01).
- Development/utvikling – Dev baser er først og fremst kortlivede og/eller ustabile, hvor endringer ikke nødvendigvis varsles på forhånd. Navngis med _devNN (feks wos_dev01).
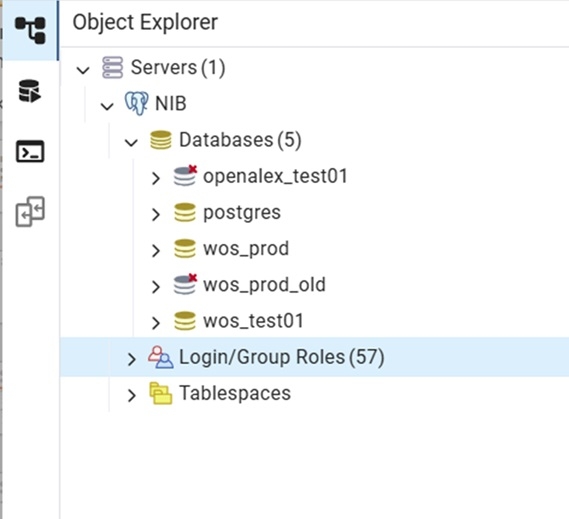
Per i dag er det kun WoS som er satt i 'prod'-versjon, det er enda ingen prod-versjon av OpenAlex. Dette skyldes at datamodellen, indikatorer, osv. fortsatt er under utvikling og testing.
Avhengig av hvilke rettigheter en bruker har, så har man tilgang til enten begge baser (alle versjoner) eller kun OpenAlex.
Oppdatering av datagrunnlag
Datagrunnlaget i begge basene oppdateres månedlig, hvorpå antall siterings- og indikatorberegninger vil endre seg. Informasjon om oppdatering av basen vil legges ut i drifts- og endringsloggen samt informeres om i bibliometriforum.
NIB har ikke kapasitet til å vedlikeholde eldre versjoner av basene. Det er derfor viktig at datasett som lastes ned for analyse blir tatt vare på lokalt, i tilfelle det oppstår behov for å rekonstruere analyser.
Tilgang til data
Direkte tilgang til NIB-data skjer pr i dag via PostgreSQL, og er derfor adgangsregulert. Dersom man har behov for slik tilgang, finner man søknadsskjema her
Matching og synkronisering med NVA
Nasjonalt vitenarkiv (NVA) er en nasjonal tjeneste for lagring, tilgjengeliggjøring av forskningsresultater og vitenskapelige publikasjoner. Tjenesten legger til rette for åpen tilgang til forskning, i tråd med nasjonale retningslinjer og er arvtager til tidligere Cristin og Brage-arkivene (institusjonelle vitenarkiv).
En av nøklene til bedre bibliometriske analyser ligger i skjæringspunktet mellom NVA og NIB, da NIB kan supplere NVA med bibliometrisk informasjon som ellers ikke er tilgjengelig i NVA. Andre veien kan NVA brukes til å berike bibliografiske databaser som tradisjonelt har et svakt datagrunnlag på institusjoner og forfatteradresser. Her har NVA forholdsvis god kontroll på norske institusjoner i UH-, helse og instituttsektor. Det betyr at det ligger til rette for mer presise avgrensninger av publikasjons-delmengder på institusjonsnivå enn det datagrunnlaget i WoS og OpenAlex støtter. Per i dag er det kun NVA/Cristin-poster fra og med 2011 og nyere som blir matchet med korresponderende poster i WoS og OpenAlex. Dette utgjør anslagsvis rundt 300 000 poster i hver database. Ikke alle poster i NVA vil kunne matches, antall poster som er matchet vil derfor variere noe mellom basene. Matching skjer kun på doi per i dag, men vil bli utvidet med andre heuristiske rutiner som også matcher på tittel, tidsskrift. år og forfattere etc.
DUCT
Matchede data kan hentes ut på to måter: enten via SQL-spørringer direkte i basen, eller via DUCT-systemet. DUCT er en tjeneste som leveres av NVA og som har med et utvalg felter fra NIB. Per i dag er det kun data fra WoS som kan hentes ut i DUCT. Merk at SQL-spørringer ikke gir tilgang til NVA-data utover en koblingsnøkkel. For å få et komplett datasett må NVA-data da hentes fra API eller andre steder.