Introduksjon til forskingsdatahandtering
Kva er forskingsdata?
Alle registreringar, nedteikningar, kjelder eller rapporteringar som samlast systematisk i samband med eit forskingsprosjekt kan sjåast på som forskingsdata. Det kan vere svar frå spørjeskjema, intervjuopptak, transkripsjonar, målingar, prøver, bilde, video, observasjonar, modellar, simuleringar eller eksperiment og statistiske analysar som brukast for å svare på eit forskingsspørsmål. Samanstilling av eksisterande data (kjeldedata) er òg ein del av dette.
Analyseskript, algoritmar, kode og programvare kan også inkluderast som ein type forskingsdata eller forskingsresultat. Om ein ser algoritmar, kode og programvare som ein annan type forskingsresultat som separat frå data, vil det likevel vere mange av dei same prinsippa og vurderingane knytt til forvaltning, deling og publisering av desse, men med nokre andre omsyn og praksis. Sjå også artikkelen om Åpen kjeldekode.
Krav og forventningar
Både nasjonale og internasjonale finansiørar stiller i dag krav eller forventningar til forskingsdatahandtering:
- Forskingsrådet krev at prosjekt som genererer forskingsdata har ein datahandteringsplan, og at data gjerast tilgjengelege så ope som mogleg.
- Horizon Europa krev datahandteringsplan for dei fleste prosjekt, og legg FAIR-prinsippa til grunn.
- Mange institusjonar i UH-sektoren har eigne retningslinjer som byggjer på dei same prinsippa.
Forskingsdatasyklusen
Forskingsdatasyklusen er eit nyttig verktøy for å visualisere og planlegge handtering av forskingsdata gjennom eit prosjekt. Syklusen kan til dømes vere eit godt utgangspunkt ved utarbeiding av ein datahandteringsplan.
Ein typisk syklus går gjennom desse fasane:
- Planlegging – definere kva data som skal samlast inn eller gjenbrukast, og utarbeide ein datahandteringsplan
- Innsamling og analyse – samle inn, handsame og analysere data, gjerne i fleire rundar
- Lagring og sikring – sikre trygg lagring og tilgangsstyring undervegs i prosjektet
- Arkivering – langtidslagre ferdige datasett i eit eigna arkiv
- Publisering og deling – gjere data tilgjengelege, så ope som mogleg og så lukka som nødvendig, i tråd med FAIR-prinsippa
- Gjenbruk – publiserte data blir kjeldedata for nye prosjekt
Syklusen er ein overordna og forenkla modell. Det vil vere stor variasjon mellom fagfelt og prosjekttypar, men dei grunnleggjande prinsippa for forsvarleg forvaltning av data gjeld for alle.
For bibliotek og andre støttetenester kan syklusen også brukast til å planlegge kva for infrastruktur og tenester som bør tilbydast til forskarar og studentar, og korleis ulike system og verktøy skal samhandle.
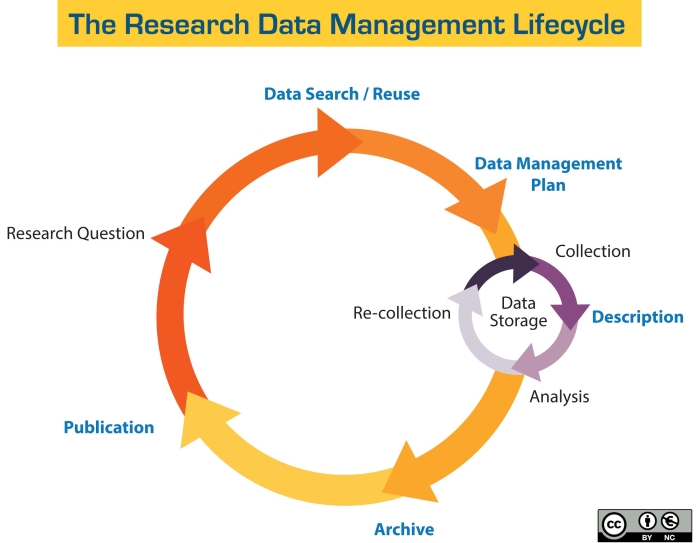
Illustrasjonen er henta frå universitetsbiblioteket ved UC Santa Cruz i California, tilgjengeleg under CC BY-NC-lisens.
Tekst: Open Science Toolbox/Sikt
Lisensiert med CC0